Most developers rely on powerful libraries like Hugging Face Transformers to work with models such as BERT (Bidirectional Encoder Representations from Transformers).
But have you ever wondered:
👉 What actually happens under the hood?
Instead of just using pre-built models, I decided to build a complete BERT-style NLP pipeline from scratch — to truly understand the mechanics behind modern language models.
What This Project Covers
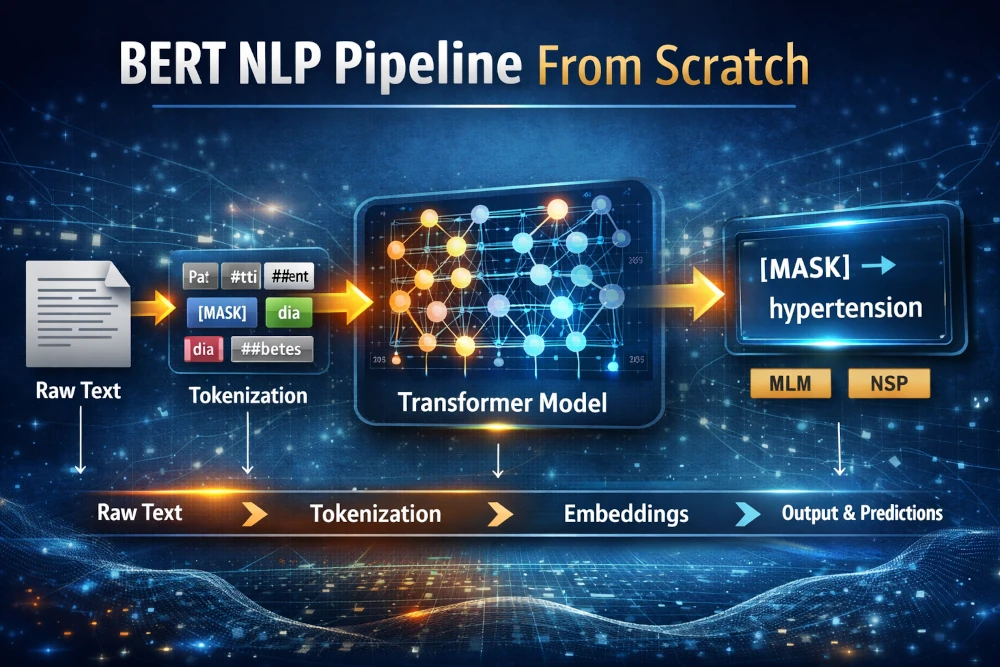
This implementation walks through the entire NLP pipeline, starting from raw text to model predictions.
⚙️ Key Components Implemented:
- Byte Pair Encoding (BPE) Tokenizer
- Subword Vocabulary Learning using merge rules
- Custom dataset for Masked Language Modeling (MLM)
- Next Sentence Prediction (NSP) pipeline
- BERT encoder stack with:
- Token embeddings
- Segment embeddings
- Positional embeddings
- Pretraining heads with combined loss function
End-to-End Pipeline Flow
Raw Text → Tokens → Contextual Embeddings → Predictions
This pipeline replicates how real-world transformer models process and understand language.
Example: Understanding Context
Input Sentence:
“Patient has [MASK] and diabetes”
👉 The model learns to predict:
“hypertension”
This shows how the model captures contextual relationships between words — not just isolated meanings.
Key Learnings & Insights
1. Tokenization is More Powerful Than You Think
Tokenization is not just preprocessing — it directly impacts how the model learns language.
Subword tokenization (BPE) helps handle:
- Rare words
- Domain-specific terms (like medical vocabulary)
- Vocabulary efficiency
2. Masked Language Modeling (MLM)
MLM enables bidirectional understanding of context — the core innovation behind BERT.
Unlike traditional models, BERT reads:
👉 Left + Right context simultaneously
3. Next Sentence Prediction (NSP)
NSP helps the model understand relationships between sentences.
This is crucial for tasks like:
- Question answering
- Document classification
- Chat systems
Why BERT is So Powerful
At its core, BERT works by:
👉 Learning context from both directions simultaneously
This bidirectional learning is what makes it outperform traditional NLP models in:
- Text classification
- Named Entity Recognition
- Semantic understanding
Explore the Project
👉 GitHub Repository:
https://github.com/shrinet/bert-from-scratch-nlp-pipeline
What’s Next?
This is Part 1 of my journey into building LLM systems from scratch.
👉 Next step: Applying this pipeline to real-world use cases — especially in domains like healthcare and intelligent systems.
Final Thoughts
- ✔️ Deeper understanding of model internals
- ✔️ Better debugging & optimization skills
- ✔️ Ability to innovate beyond libraries
Don’t just use AI — understand it.