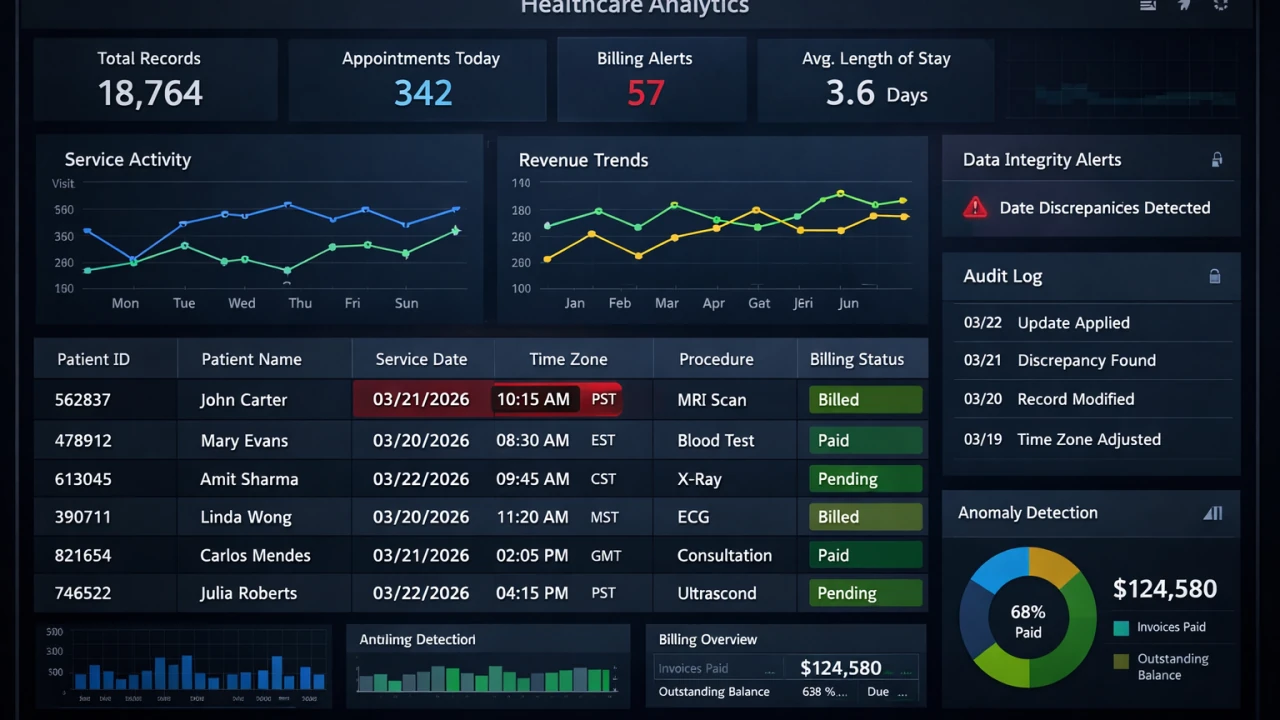
Recently, I encountered a production data anomaly.
Some service records had their service date shifted by ±1 day.
At first glance, it looked minor. It wasn’t.
🔍 The Hidden Complexity
What made this dangerous wasn’t the shift itself — it was the uncertainty.
There was:
- ❌ No clear deployment window
- 🌍 Multiple user time zones
- 🎯 Only a subset of records affected
- 🧩 Historical code paths that had evolved over time
In healthcare systems, a one-day shift isn’t cosmetic.
It affects:
- 📊 Regulatory reporting
- 💳 Billing cycles
- 📈 Downstream analytics
- 🔐 And most importantly — trust in data
And once trust erodes, every number becomes questionable.
🧠 We Treated It as a Data Engineering Problem — Not a Patch
Rather than applying a blanket correction, I approached it systematically.
🔬 The Approach
- Profiled historical data patterns at scale
- Identified deterministic corruption signatures
- Formulated timezone transformation hypotheses
- Validated cohorts mathematically before touching data
- Applied corrections only where evidence was conclusive
- Built audit and rollback safeguards into the remediation
🛑 The Principle I Follow
If it’s not provable, don’t fix it automatically.
What looked like random drift turned out to be structured transformation artifacts.
Quick fixes solve visible symptoms.
Disciplined engineering protects long-term integrity.
🏗 Engineering Maturity
Engineering maturity isn’t measured by how fast you patch —
It’s measured by how safely you correct historical entropy.
Fixing production data requires:
- 🧠 Statistical thinking
- ⚙ Systems awareness
- 🛡 Operational safeguards
- 🧭 And the discipline to avoid “quick fixes”
💬 Curious to Hear From Others
For those working in regulated or large-scale systems:
- Do you rely strictly on deterministic correction rules?
- Have you ever applied probabilistic remediation?
- How do you balance speed vs auditability?
Would genuinely value insights from other engineers and data leaders.